Production-проекты
Email Digest Generator
Автоматизированная платформа создания ежемесячных email-дайджестов для крупного производителя электроники. Полный цикл: парсинг контента → AI-генерация вариантов → аналитический скоринг на основе 262 шаблонов → редакторский UI → экспорт для дизайнеров. Отдельная PROD-версия на российских AI (YandexGPT, GigaChat) для соответствия 152-ФЗ.
AI Agents Platform
Мультиагентная платформа на Dify с двумя специализированными AI-агентами для CRM-команды крупного производителя электроники. Кастомные микросервисы: File Storage API (16 эндпоинтов) + Analytics API (12 эндпоинтов). Anti-hallucination дизайн, кросс-чат память, 24 инструмента агента.
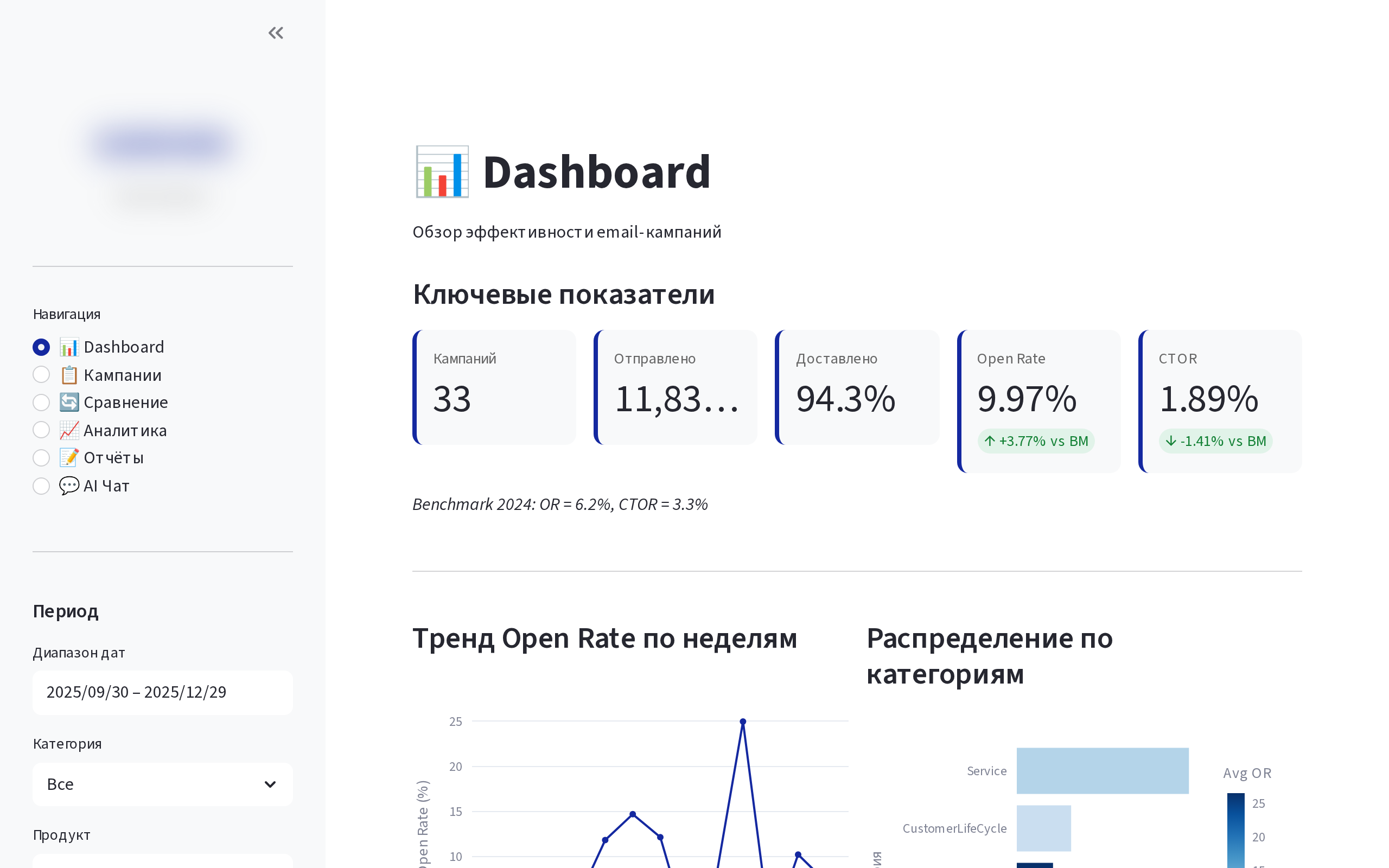
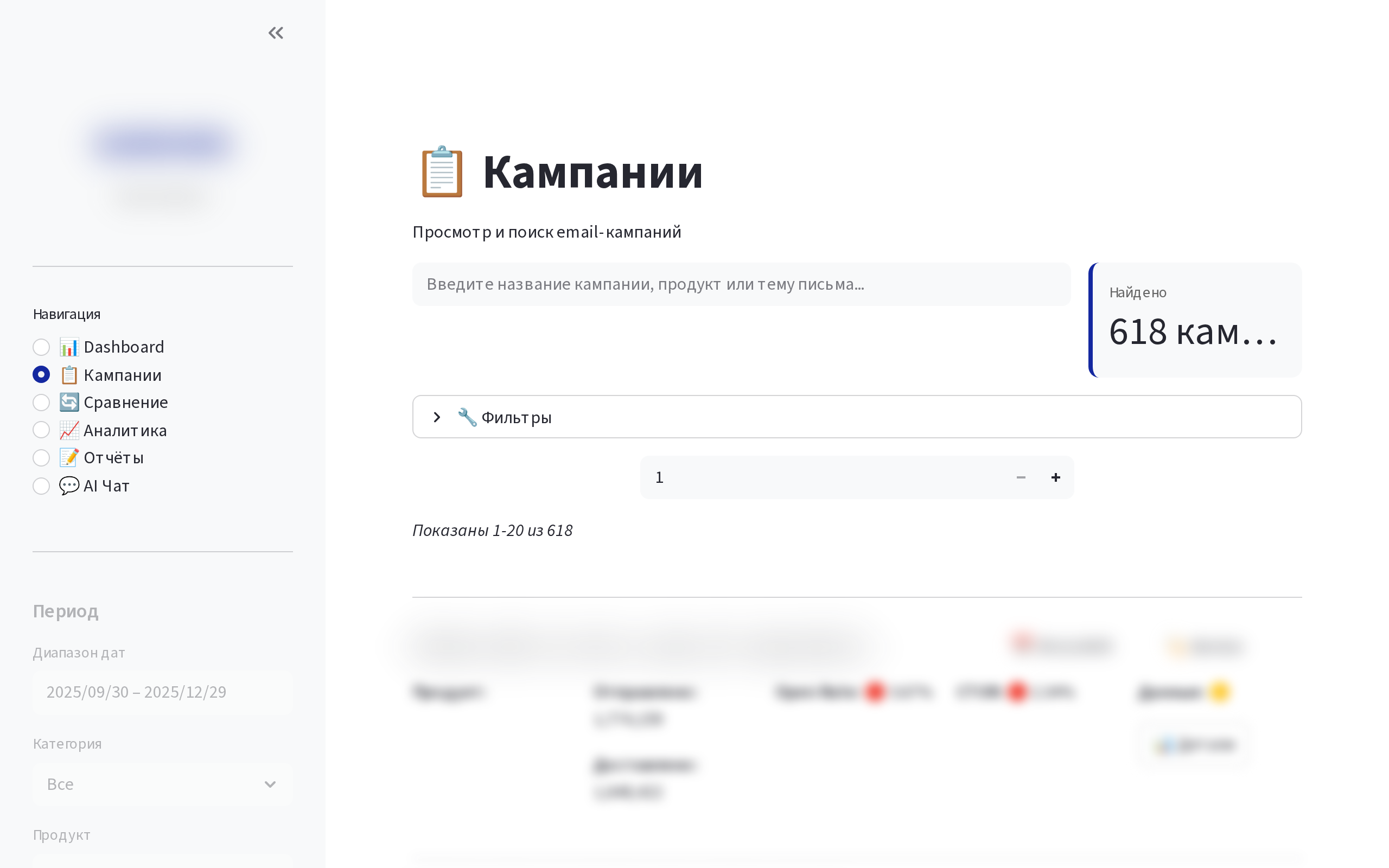
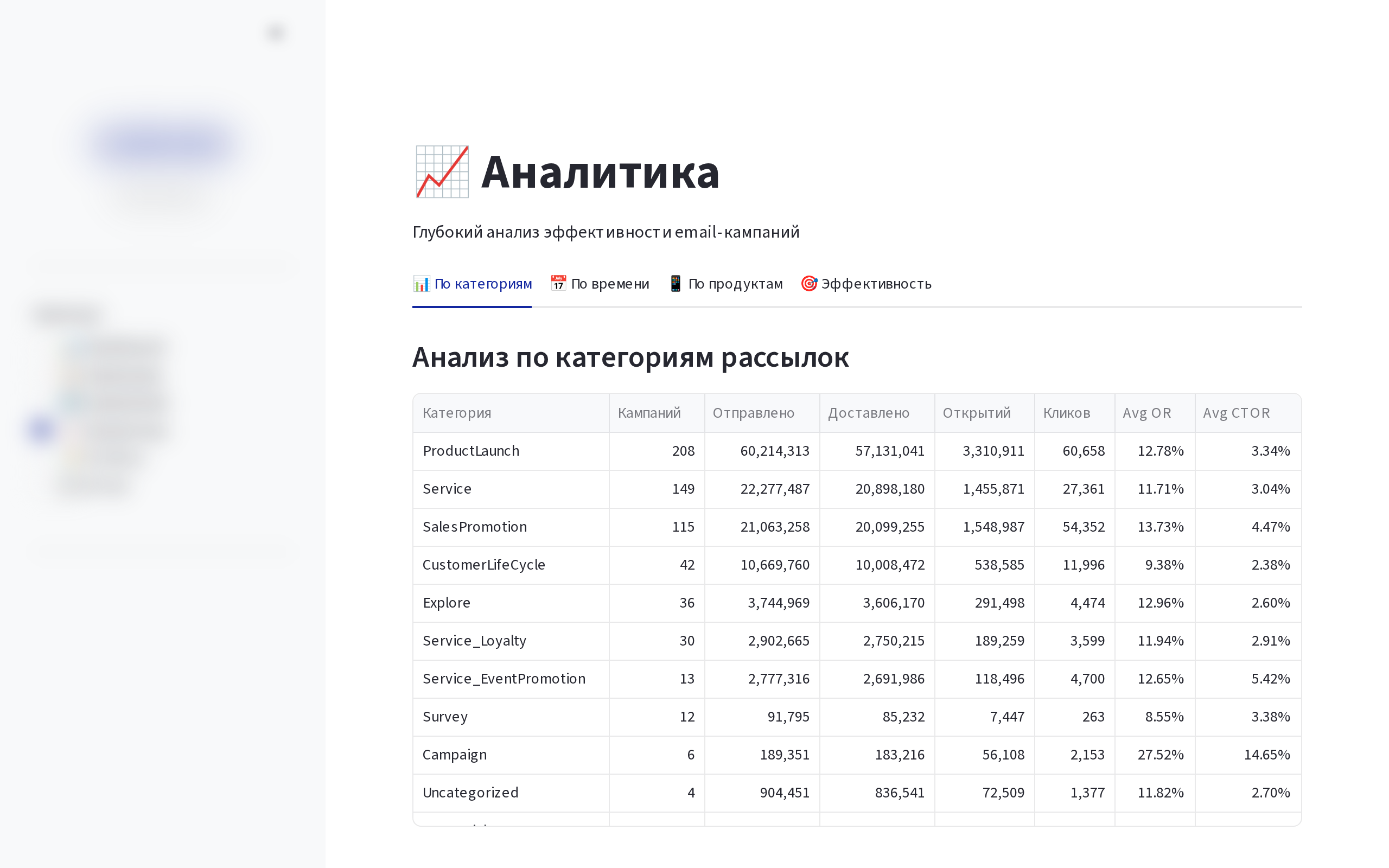
Email Analytics
AI-powered платформа аналитики email-кампаний для крупного производителя электроники. Анализ метрик 620+ рассылок, ~6000 click-элементов, генерация AI-инсайтов, создание брендированных отчётов PPTX/PDF и визуализаций click-map.
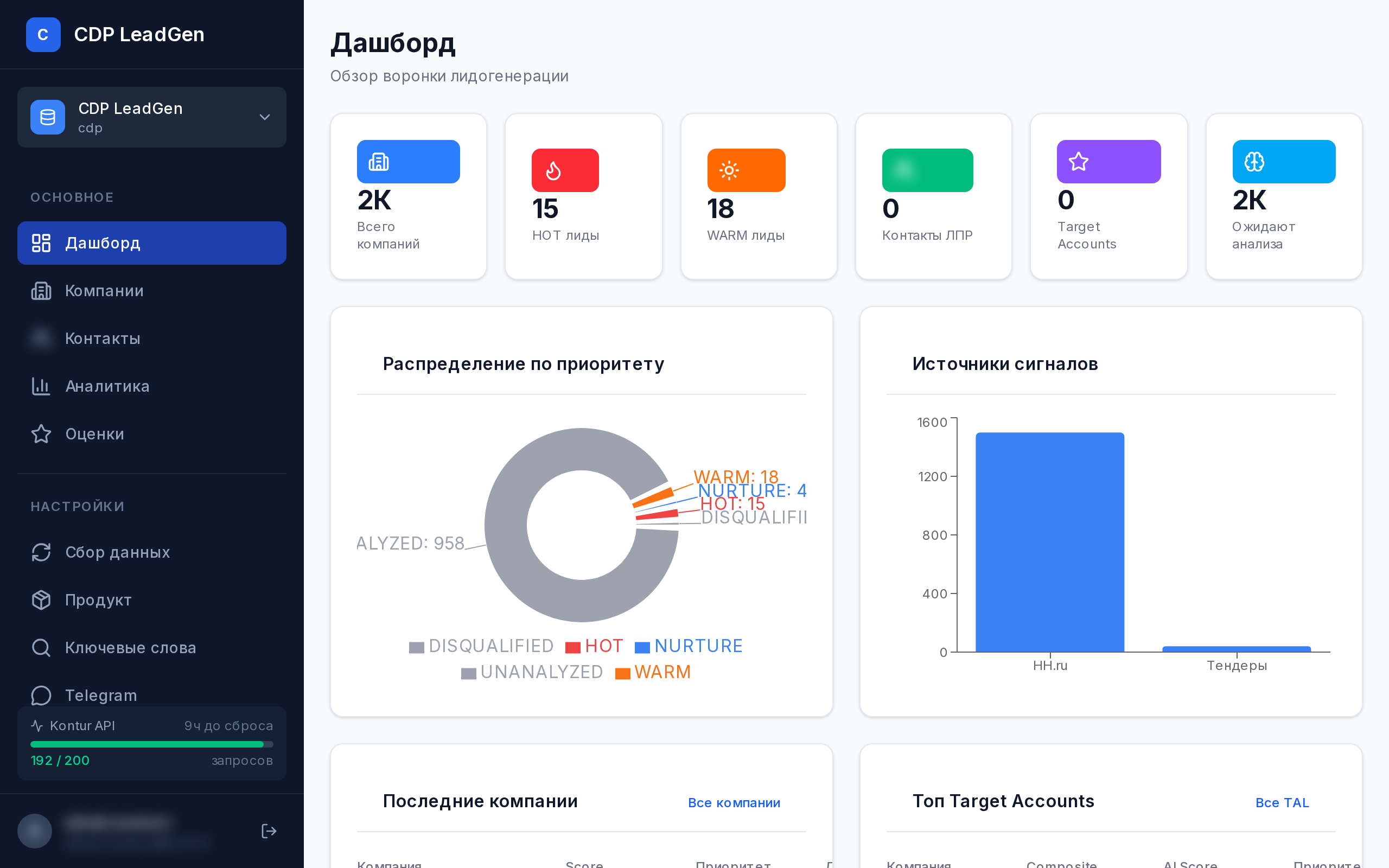
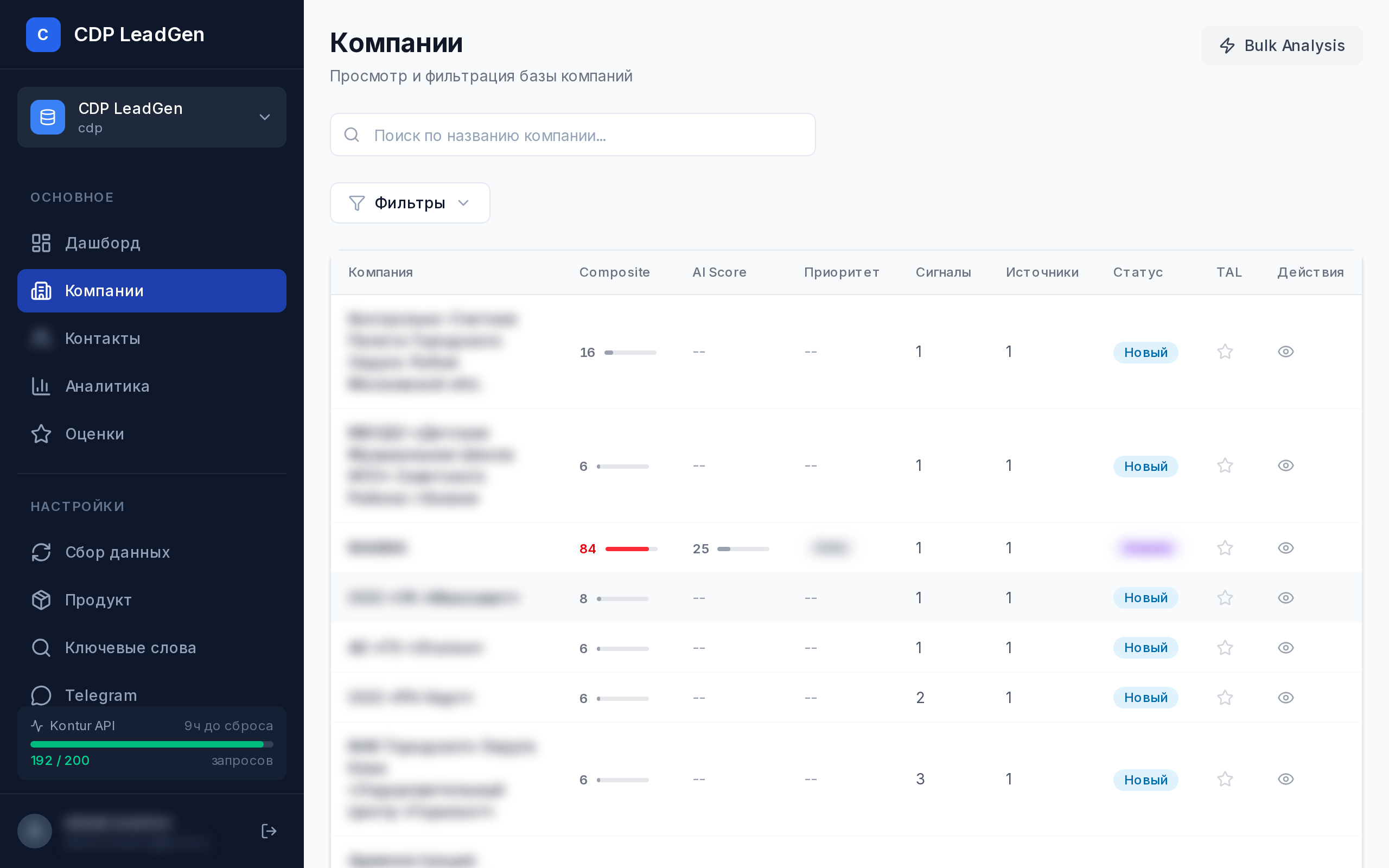
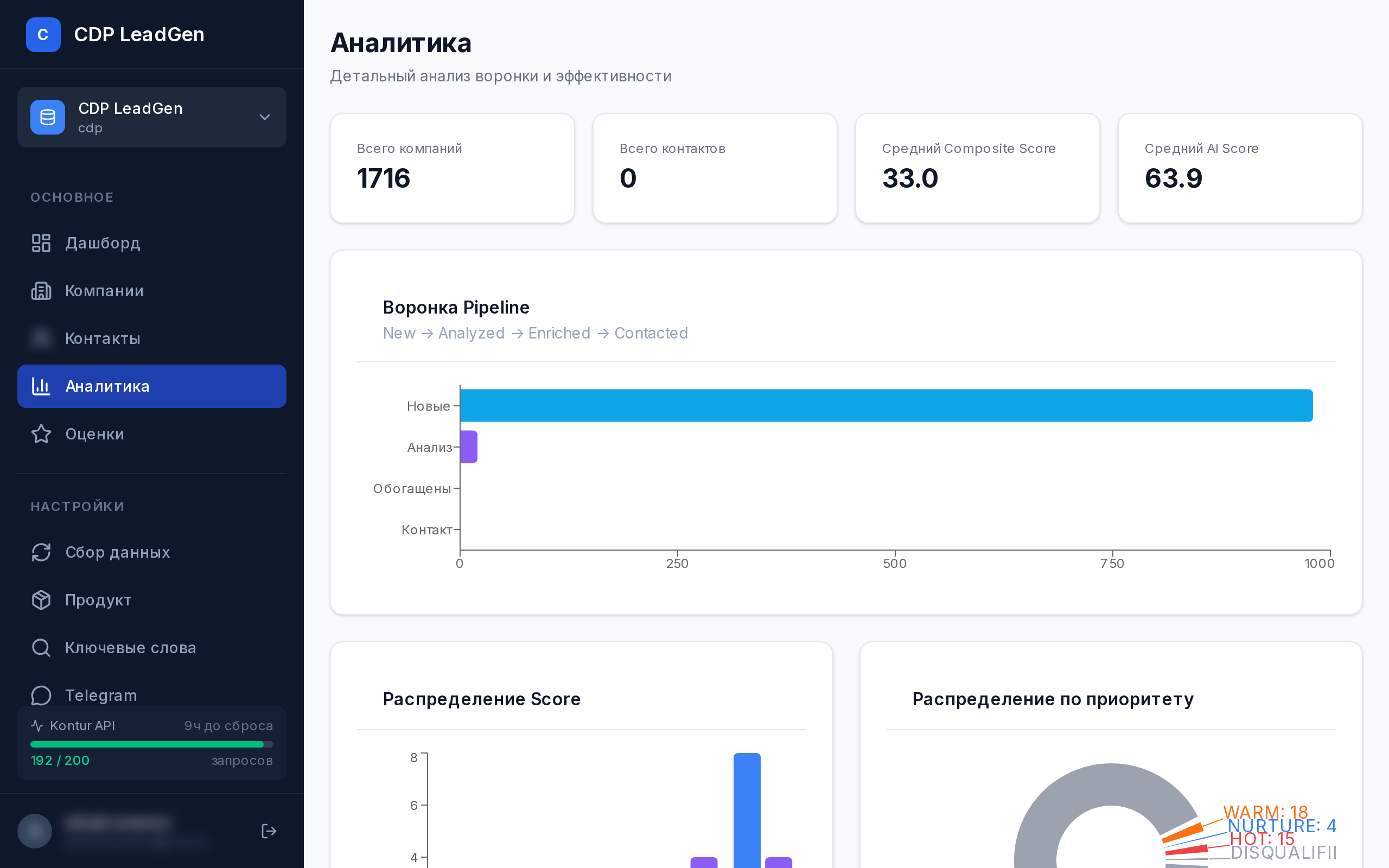
CDP LeadGen
Микросервисная платформа автоматического поиска и AI-оценки потенциальных клиентов для продажи CDP-решений. Агрегирует сигналы из 4 источников, применяет многоуровневый скоринг с time decay.
HR Automate
Full-stack платформа автоматизации HR-процессов для full-service маркетингового агентства. 11 модулей, 9 cron-задач, 5 OAuth-интеграций. Параллельные среды в EU и РФ с маршрутизацией между западными и российскими AI-моделями в зависимости от наличия персональных данных (152-ФЗ).
CRM Bulk Analytics
Unified-платформа аналитики bulk-коммуникаций (email + Telegram + MAX) для крупного международного FMCG-холдинга — несколько брендов в одной системе. Заменила 3 ручных PPTX-отчёта. Brief Oracle прогнозирует OR/CTOR/Unsub новой кампании по similarity-search через pgvector HNSW.
SMS Analytics
Автоматический сбор, классификация и отчётность по SMS/Telegram-сообщениям нескольких брендов. Заменила 8 workflow на n8n единым FastAPI-сервисом. 6 SMSC-аккаунтов, 7 брендов, ~10 000 сообщений/неделю.
Claude Workspaces
Платформа предоставления изолированных сред Claude Code (VS Code в браузере + файловый менеджер) для 10 одновременных пользователей с библиотекой из 19 навыков.
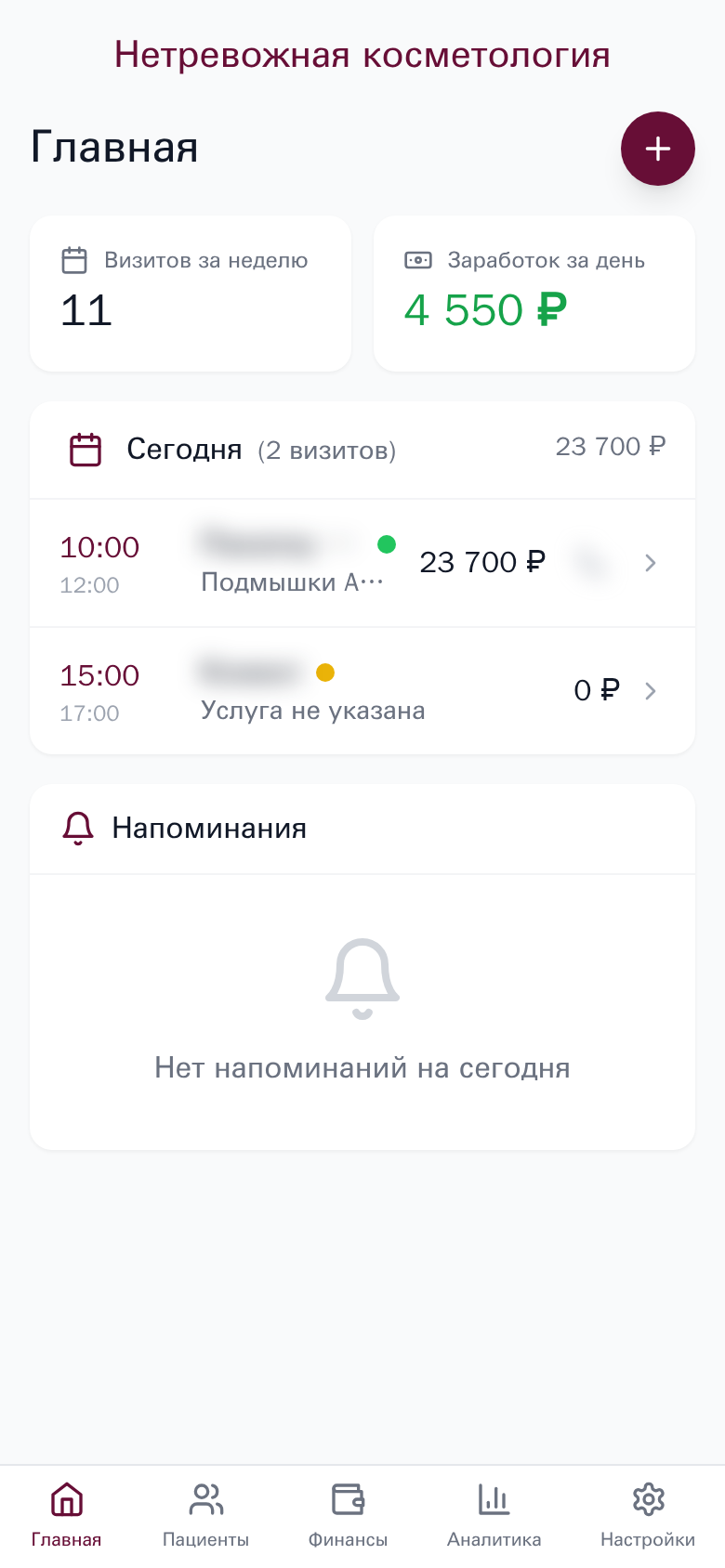
CosmoDoc
Mobile-first Progressive Web App для управления косметологической клиникой. Синхронизация записей пациентов из YClients, отслеживание визитов с фото до/после, расчёт заработка врача.
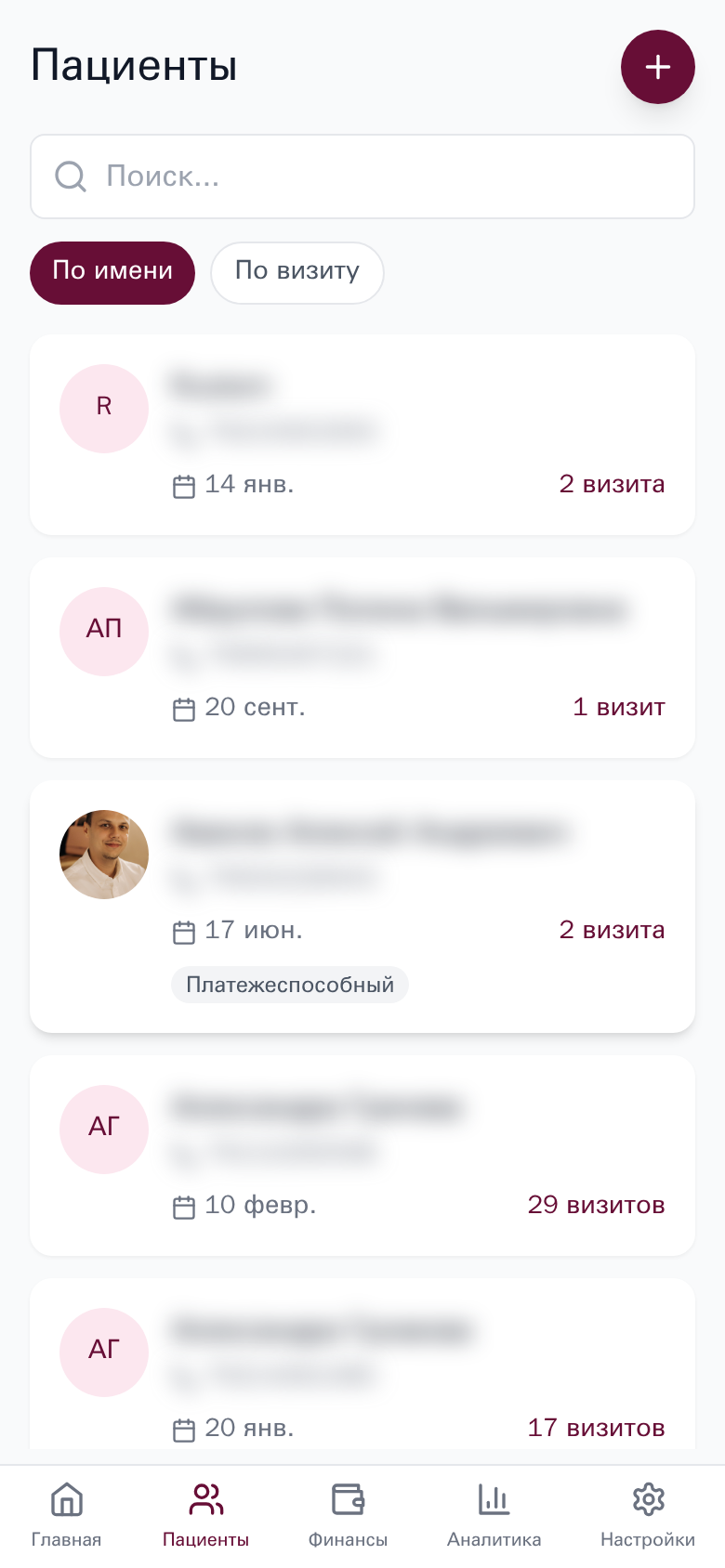
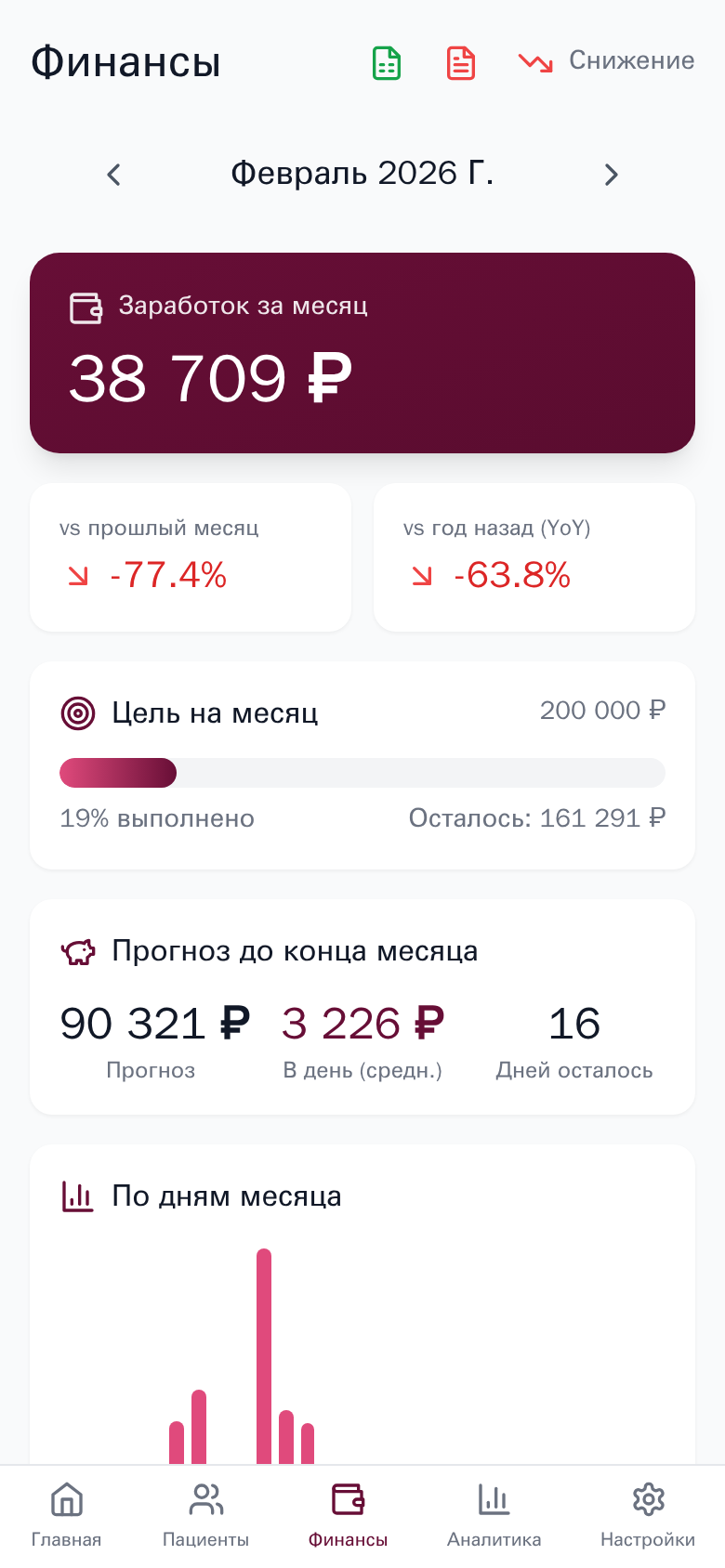
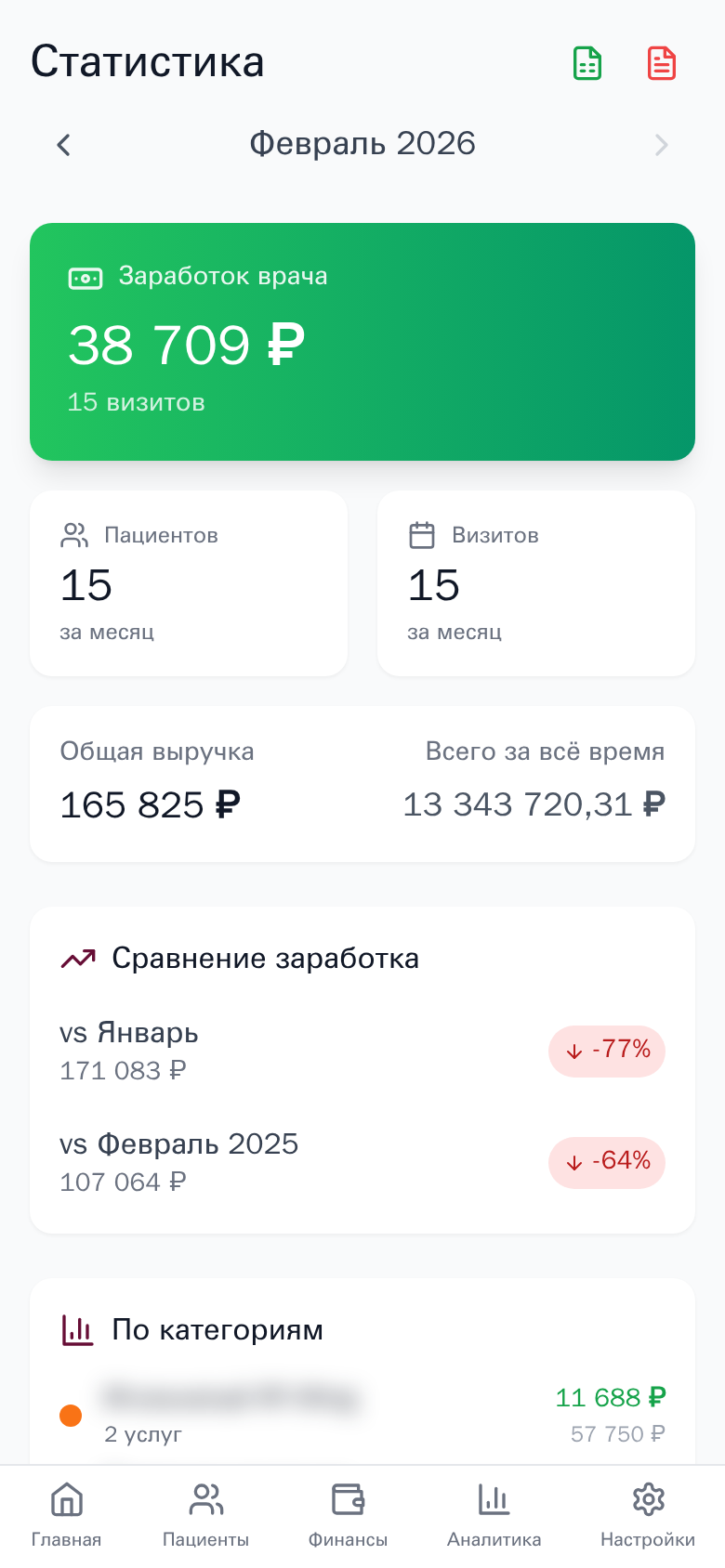
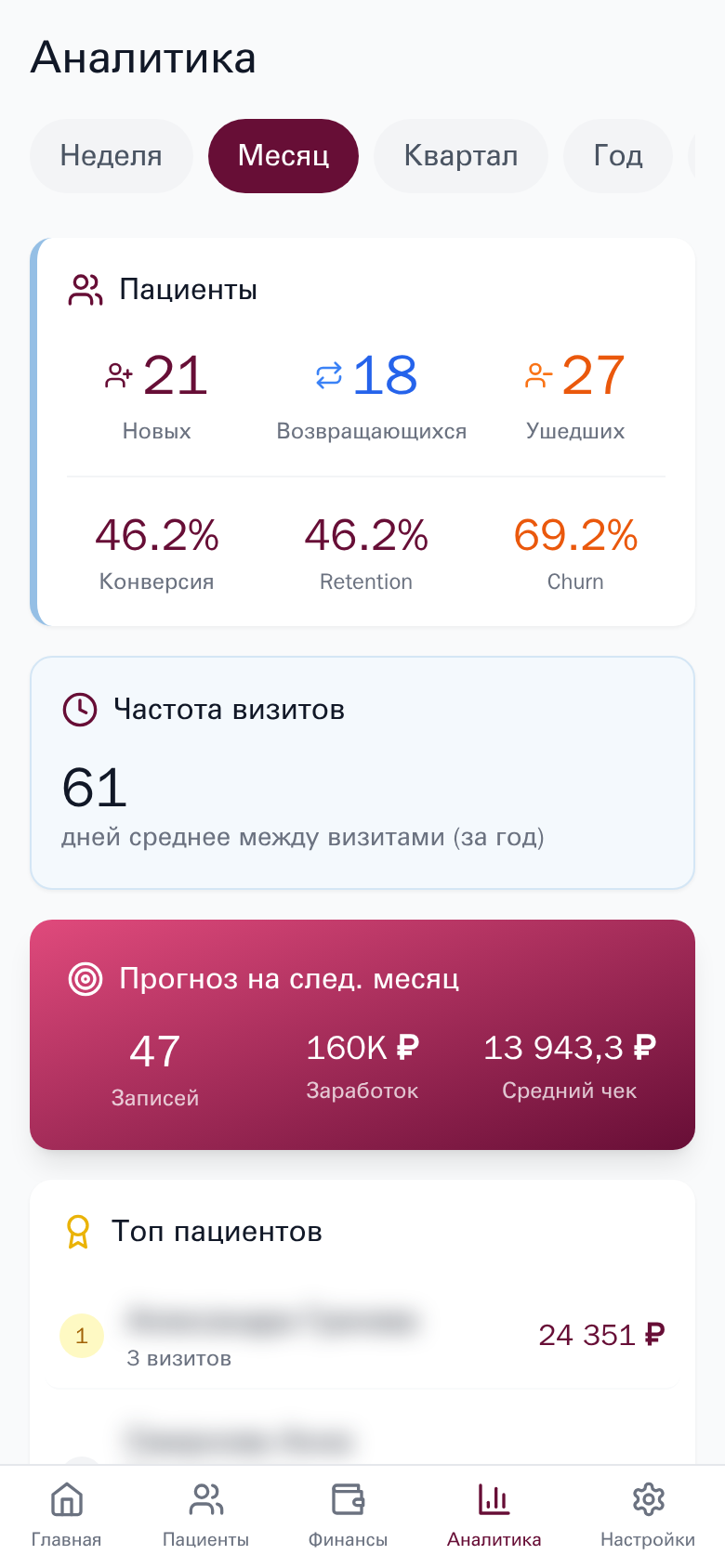
Plant Care
Progressive Web App с AI-рекомендациями для ухода за комнатными растениями. Расписание полива с push-уведомлениями, идентификация растений, персонализированные советы от Claude Haiku.
Chronicler's Forge
Веб-приложение для проведения D&D-кампаний: цифровые листы персонажей, карты с маркерами, Suno AI музыка, fal.ai генерация изображений, импорт контента из Telegram. Real-time синхронизация между DM и игроками.
NPS Classifier
Мультибэкенд LLM-прокси для классификации NPS-комментариев. Поддерживает OpenRouter, Z.ai, LM Studio с автоматическим fallback и бенчмаркингом.
hh-auto
Автоматизация полного цикла поиска работы на hh.ru: поиск вакансий через API, AI-скоринг (Gemini), автогенерация сопроводительных писем (Claude Sonnet), автоматический отклик через Playwright.
AI Caller
Система автоматических звонков с AI: распознавание речи (Yandex STT), генерация ответов (OpenRouter AI), синтез речи (Yandex TTS). Real-time voice processing через WebSocket.